Data Curation Guidelines
Adding new entities and relationships via UI 4
Step 1: Check for Duplicates 4
Step 2: Check for Wikidata entry 4
Step 3: Fill out basic information 5
Step 5: Add additional relationships 9
Adding new competencies and relationships via Excel import 10
Deactivating / deleting entities & relationships 11
Data Curation Guidelines
ProfileMap’s search and analysis features rely on a controlled knowledge base, the so-called ontology. The quality and completeness of this ontology will strongly affect the quality of the search and the analyses performed within ProfileMap. ProfileMap’s User Manual provides the documentation of the data curation functionalities used for augmenting, correcting, and maintaining the ontology. The guidelines provided in this document provide additional details and best practices to facilitate the user to efficiently set-up and maintain a comprehensive and effective ontology.
Ontology
An ontology is a graph used to represent knowledge. The nodes of the graph mostly correspond to entities. An entity can be a competency, a language, a certificate, or a client. In addition to that internally also translations and synonyms are modelled as nodes though this doesn’t affect the data curation work. The edges of the graph are directed and called relationships. They define how two entities are related to each other. Relationships have types and these types convey meaning.
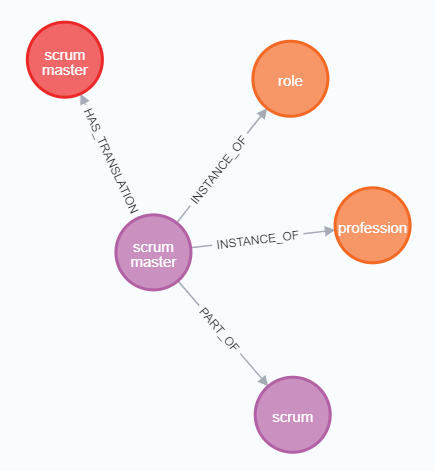
For example, this graph represents the information stored in the ontology of the entity scrum master. The entity is called “scrum master” in English (see the term in the purple node in the middle), it is called “scrum master” in German (see the red node) and has three relationships to other entities. The INSTANCE_OF relationship indicates that the entity the edge is originating from is a more specific kind of entity of the one the edge going to. So, in this case “scrum master” is a specific kind of profession and a specific kind of role. The PART_OF relationship indicates that the entity this edge is going to is made up of multiple parts. In this case, having a scrum master is part of the scrum process.
As described in the User Manual, the ontology is used in the search filter to allow ProfileMap to find candidates with indirectly matching profiles and affects the order in which the candidates are displayed.
Categorization
As described in the User Manual the categorization (or taxonomy how it is also sometimes referred to) of entities is used to structure the profile and to allow filtering and selecting entities based on the defined categorization. Typically, the categorization is based on customs and conventions of the respective customer. It is recommended to choose the categories and subcategories to make it as natural as possible for the users to find the entities they are looking for. Since this is customer-specific, we do not provide a general recommendation on how to categorize.
Adding new entities and relationships via UI
ProfileMap comes with a comprehensive ontology. In addition to that, each customer can adapt his or her ontology based on their respective requirements. Possible adaptations are adding and/or deleting entities and/or relationships. The functionality ProfileMap provides for this is described in the User Manual chapter called “Data Curation”. This section provides further detail information on how to choose entities, synonyms, and relationships to add or delete. In addition to that, it is possible to add competencies using an Excel template. This option can be attractive if many competencies should be added to the system at once as might be the case during the rollout phase, especially if many competencies from domains not yet fully covered by ProfileMap’s standard ontology should be included. The provided template will be described in the section Adding new competencies and relationships via Excel import, though many of the recommendations provided in this section apply likewise to the Excel template.
Step 1: Check for Duplicates
Search for the name, translations, and synonyms of the entity using the entity filter on the data curation screen (see image) to make sure that the entity you want to add doesn’t exist in the system already. Only proceed if it doesn’t.

Step 2: Check for Wikidata entry
Search for the name, translations, and synonyms on https://www.wikidata.org/ to see whether a Wikidata entry for your entity exists. If so, copy the Wikidata-ID into the entity creation form.
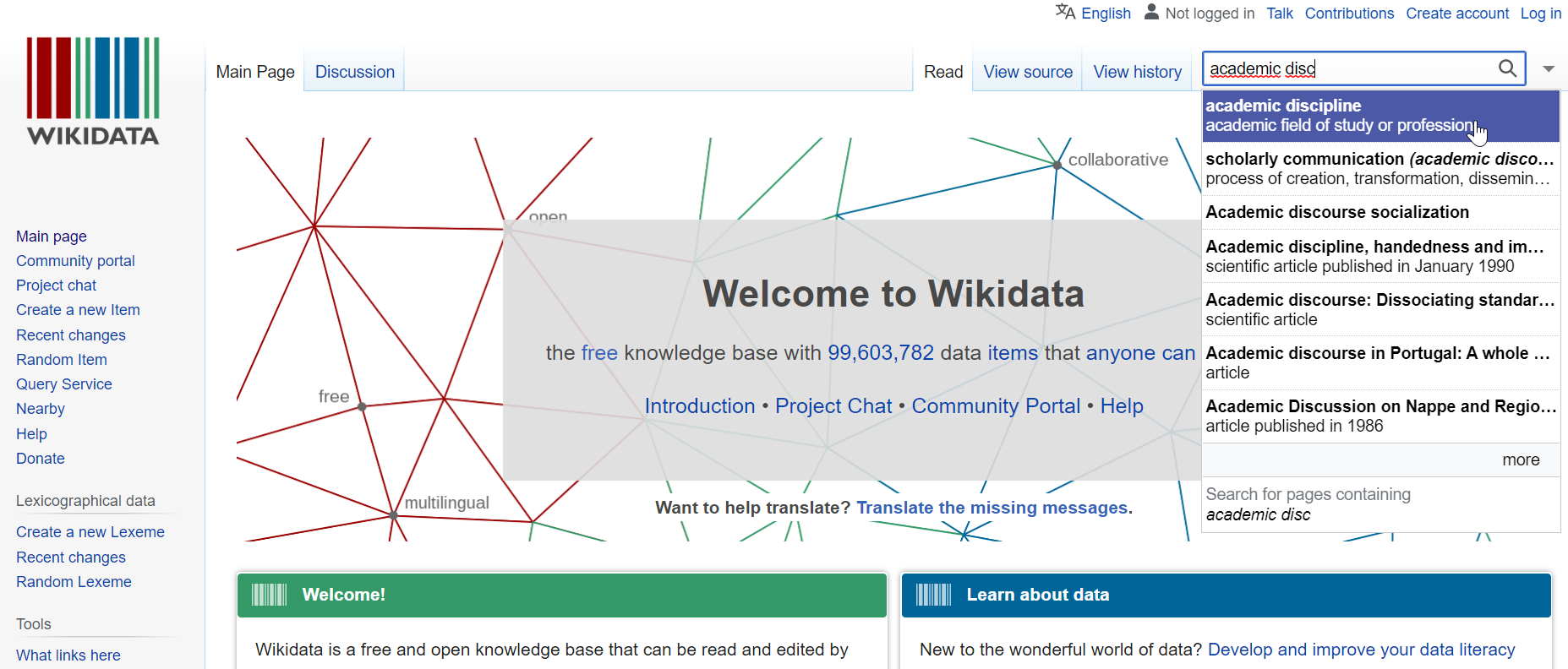
One can search for terms in Wikidata using the search bar in the top right corner of the website. If no fitting Wikidata concept is found, leave the Wikidata ID field empty and go on with steps 3-5.
Step 3: Fill out basic information
If you entered a valid Wikidata ID, click the reload button. This will automatically fill the fields of the entity creation form and you can skip steps 4 and 5.
Otherwise, fill out the name, aliases, and description for both English and German in the entity creation form by yourself.
Typically, there are different spellings of the same term as well as common misspellings that the system should ideally also recognize. There are improvements for ProfileMap planned that will allow the system to detect certain variations of terms automatically, so that not all variations need to be entered as synonyms. The following table provides an overview on where it is recommended to include both spellings and where one spelling suffices either now or in the future once the planned improvements of ProfileMap’s normalization process are integrated.
| Case | Example | Currently Matched | Extension Planned | Recommendation |
| Compound words | “Projektmanagement” and “Projekt Management” | No | No | Enter both the compound word and the misspelling |
| Different separators | “Project Management”, “Project-Management”, “Project_Management” and “Project/Management” | No | Yes | Enter one spelling, with future extensions more and more of the alternative spellings will be matched |
| Singular / Plural | “test automation” and “test automations” | No | Yes | Enter the singular spelling the plural one will be normalized with a future extension |
| Verb Forms | “debug”, “debugs”, “debugging” and “debugged” | No | Yes | Enter the base form the other forms will be normalized with a future extension |
| Camel Cases | “ProfileMap” and “Profile Map” | No | Yes | Enter the more common spelling. The alternative one will be matched with a future extension |
| Two skills in one term | „Regressions- und Integrationstests“ | No | Yes | Only include the individual terms (“Regressionstest” and “Integrationstest” in the example), not the combined term as well. Identifying the first of the two skills is a big challenge to the system, so it might take time until this matching is available, and it might be more error-prone than other normalizations. But we do not recommend adding all combinations because of the effort to do so and the effects on the ontology model. |
| Skill including a “and” | “CI/CD”, “CI / CD”, “CI & CD”, “CI and CD”, “Continuous Integration and Continuous Deployment”, “Continuous Integration / Continuous Deployment” and “Continuous Integration & Continuous Deployment” | No | Yes | In comparison to the “Two skills in one term” case, here the terms typically appear together and are to be considered a single skill. In this case, only include one spelling for the full version and one spelling for the abbreviated one (if there is one as in the example). The white space and different versions of combining the two terms (“/”, “&”, “and”) will be normalized with future extensions. |
Whether to include software versions, like “Ubuntu 20.10”, “Ubuntu 21.04” and so on, or not, depends on whether the users intend to formulate such specific search requests. There isn’t a general recommendation from minnosphere on whether to include them or not. It is also possible to only include them in certain areas and be more general in others. If they are connected to a more general entity (“Ubuntu” in the example above) using an INSTANCE_OF relationship, candidates only having entities including the software version but not the more general skill will also be found, when searching for the more general skill.
Sometimes there are competencies that seem to be formed by combining two existing competencies, like “linux firewall” seems to be made up of the two separate competencies “linux” and “firewall”. There are two ways of dealing with situations like this. Either the combined term is not entered in the ontology and users simply search for the two entities (here “linux” and “firewall”) and receive candidates that have both in their profile. This can lead to situations where candidates look appropriate but aren’t, like e. g. if a candidate knows about other aspects of “linux” and only about a specific other “firewall”. However, such cases tend to be rare, and this approach reduces the number of entities that need to be maintained by the data curators.
If such detailed distinctions are required, on the other hand, the recommended way to do this is the following: add a new entity (in the example “linux firewall”) and create appropriate relationships to the two other entities. Often the second word is the headword of a term, and the new entity is a special kind of the entity corresponding to the headword. In the example, “linux firewall” is a special kind of “firewall”. So, it should be connected to “firewall” with an INSTANCE_OF relationship. The “linux firewall” here is also a part of the whole linux system. Thus, a PART_OF relationship should be create between “linux firewall” and “linux”.
A good description helps the system to use the entity better. It might in the future e. g. contribute to the ranking of candidates in the search result list or to distinguishing between ambiguous terms. Also, relationships will be used to disambiguate terms. Thus, curating these well will contribute to better disambiguation in the future.
⚠At the moment there isn’t yet a disambiguation algorithm included when extracting terms from text. Thus, all terms that have a matching synonym are displayed. If a very rare entity has a synonym that happens to also be a very commonly used word (like “automatic network dialing” being abbreviated as “and”), this entity will be suggested every time the common word appears in a text. It might be more beneficial from a UX perspective to not include this synonym for the very rare entity to spare the user the need to often remove the entity manually.
Step 4: Add parent concept
Add a parent concept for your skill by creating an INSTANCE_OF relationship to a broader category. Choose the most specific applicable category, e. g. better “Test Automation Framework” than “Software”.
Typical parent concepts for competencies include:
| Wikidata-ID | Term | Example Children |
| Q11862829 | Academic Discipline | Statistics, Human Resource Management, Robotics, Marketing |
| Q66747126 | Computer Science Term | Systems Programming, Debugging |
| Q188267 | Programming Paradigm | Functional Programming, Big Data, Event-Driven Programming |
| Q188522 | Software Testing | White-box testing, data-driven testing, test automation |
| Q7397 | Software | Netscape, Google Analytics, Adobe Reader 5.0 |
| Q1077784 | Programming Tool | Automake, lint, pkg-config, Windows driver frameworks |
| Q271680 | Software Framework | OpenCL, Apache Forrest, Puppet |
| Q188860 | Software Library | Qt, Akka, Java Media Framework, Apache pdfbox |
| Q15618492 | Software Testing Tool | Tricentis Tosca, Apache JMeter, Oracle Application Testing Suite |
| Q7705752 | Test Automation Framework | Unity, JUnit, mojotest, Selenium |
| Q1330336 | Web Framework | React, Angular, JavaServer Faces, django |
| Q9143 | Programming Language | Java, Scala, C++, Python |
| Q9135 | Operating System | Windows 8.1, Nintendo IOS, webOS |
| Q241317 | Computing Platform | Java Virtual Machine, Cygwin, MS DOS, Platform as a service |
| Q13741 | Integrated Development Environment | Intellij IDEA, Eclipse, Xcode |
| Q2727468 | Build Automation | Gitlab, cmake, Gradle, sbt |
| Q891055 | Package Management System | Apache Maven, npm, Homebrew |
| Q1480561 | Issue Tracking System | Jira, Trello, Redmine |
| Q176165 | Database Management System | Redis, Apache HBase, Microsoft Access |
| Q595971 | Graph Database | Blazegraph, Amazon Neptune, Neo4j |
| Q3932296 | Relational Database | MySQL, Amazon Redshift, Postgres |
| Q82231 | NoSQL Database Management System | MongoDB, Amazon DynamoDB, Apache Cassandra, OrientDB |
| – | SAP Product | SAP Cloud Platform, SAP Analytics, SAP Business One |
| – | SAP Functional Module | SAP Quality Management, SAP Financial Services, SAP Customer Service |
| Q1378470 | Software Development Methodology | Waterfall Model, Agile Software Development, Scrum, Continuous Delivery |
| Q8187769 | Economic Activity | Software as a Service, Accounting, Customer Relationship Management |
| Q131093 | Content Management System | Typo3, WordPress, Drupal, Microsoft Sharepoint |
| Q8148 | Industry | Robotics, Human Resource Management, Computer Security |
| Q15910354 | Soft Skills | – |
Parent concepts are used to allow for indirect searches. If a user e. g. searches for a candidate who knows about “Build Automation”, he or she will also receive candidates that have more specific competencies like “Gitlab” or “cmake” but not “Build Automation” itself in their profiles. This function works transitively. So, if the user chooses “Functional Programming Language” as a parent term whose parent term in turn is “Programming Language”, his or her new entity will be matched both if one searches for a “Functional Programming Language” but also if one searches for the more general “Programming Language”. Choosing a more specific parent term allows for more of these indirect searches to take effect.
Typical parent concepts for certificates:
| Wikidata-ID | Term | Example Children |
| – | Project Management Certifications | Certified Scrum Master, PMI Professional Project Manager |
| – | Applications | Basics SAP Solution Manager, Microsoft Office User Specialist |
| – | Test Management | Tosca certified specialist, SQS AG – Initial Training, msg systems intensive training certified tester |
Currently, there is not a mechanism for adding categories for certificates or clients. If you require additional categories, please get in touch with the ProfileMap help desk (e-mail to msg.ProfileMap.HelpDesk@msg.group).
Parent concept for languages:
| Wikidata-ID | Term | Example Children |
| Q34770 | Language | Arabic, Spanish, Italian |
Step 5: Add additional relationships
Choose additional relationships to concepts. Explanations of recommended relationships:
| Relationship | Explanation | Examples |
| INSTANCE_OF | Relationship from a more specific concept to a more general one (usually one can form a is-a sentence between the two like e. g. Java is a programming language) | Java
– INSTANCE_OF -> Programming Language Waterfall model – INSTANCE_OF -> Software development methodology |
| PART_OF | Relationship to a bigger concept from the concepts it consists of (usually one can form a is-made-up-of sentence like e. g. artificial intelligence is made up of machine learning and logics) | Microsoft Access
– PART_OF -> Microsoft Office Machine learning – PART_OF -> Artificial intelligence |
| USE | Relationship between a tool and a method or another tool that is used by it | Git
– USE -> Version control Apache Maven – USE -> Build management IBM Lotus Notes Expeditor – USE -> OSGi |
| PROGRAMMING_LANGUAGE | The programming language of a tool. This is important to set between a software library and a programming language. | Apache commons
– PROGRAMMING_LANGUAGE -> Java Pandas – PROGRAMMING_LANGUAGE -> Python |
| PROGRAMMING_PARADIGM | A paradigm present in a programming language | Clojure
– PROGRAMMING_PARADIGM -> Functional programming C# – PROGRAMMING_PARADIGM -> Object-oriented programming |
| OPERATING_SYSTEM | The operating system on which a tool is available, or the operating system installed on a specific hardware | iOS SDK
– OPERATING_SYSTEM -> macOS Git – OPERATING_SYSTEM -> Cross-platform |
For all these relationships multiple relationships can be set for a single skill.
⚠It is recommended not to use the relationship types SUBCLASS_OF, TRANSLATION, ALSO_KNOWN_AS, DEVELOPER, BELONGS_TO or CATEGORY_OF when creating relationships in the entity creation form.
⚠The INSTANCE_OF, SUBCLASS_OF, USE, PART_OF and PROGRAMMING_LANGUAGE relationships are or will be used for indirect searches as described above. The general-specific pattern described above is only one of multiple indirect search patterns. If one connects entities wrongly using these relationship types this will have effects on which candidates are found by the search, on which terms are displayed as related terms in the side-by-side comparison and possibly also on the search performance if significantly more candidates are returned.
Adding new competencies and relationships via Excel import

The Excel template provided for adding competencies using a script includes the following fields:
| Field | Required | Values | Description |
| Category | No | String | The field can be used to organize the competencies in the same way they will be categorized in ProfileMap. Taxonomy relationships between the skill and the category will be created during import. |
| Skill name EN | Yes | String | The English name of the competency. |
| Skill name DE | Yes | String | The German name of the competency. |
| Wikidata ID | No | Valid Wikidata-ID | If a Wikidata-ID exists, it can be set here. If a Wikidata-ID is set the data from the template and from Wikidata will be combined. The names of the competency will be the ones from the template. The synonyms contain the Wikidata names (if different from the ones in the template) and both the synonyms from the template and from Wikidata. Likewise, the relationships both from the template and from Wikidata will be created. The descriptions will be set based on the contents of the template. If a description entry is left empty in the template, the description from Wikidata will be used instead. |
| Synonyms EN | No | Comma-separated list | The English synonyms of the competency. |
| Synonyms DE | No | Comma-separated list | The German synonyms of the competency. |
| Relationships | No | Relationship list | The relationships to other entities. It is possible to create relationships to other entities in the same template if they are in earlier rows. |
| Description EN | No | String | A continuous text describing the entity in English. |
| Description DE | No | String | A continuous text describing the entity in German. |
| Comments | No | String | A field that can be used for comments during the process of filling out the template. The column just as all other columns to the right will be ignored during import. |
A relationship list here refers to a comma-separated list of relationship type and entity. The entity is represented by its Wikidata-ID or its name.
Example: PART_OF Q456157, SUBCLASS_OF sap product
⚠ To add new entities, the names of the entities that should be added using the template must be different from the names of the entities already in the ontology. If the German or English entity name or the entered Wikidata ID already exist, the existing entity will be updated instead of creating a new one. An entity is updated by adding the synonyms and relationships given in the template that weren’t existing already. In addition to that, if there are descriptions given in the template, they will be used to overwrite the existing descriptions.
⚠ All recommendations concerning adding entities and relationships from the previous section, especially those concerning choosing sensible values for the different fields, also apply to filling out the Excel template.
Once the template is filled out, your ProfileMap contact person will perform the import. Get in contact with the ProfileMap help desk (e-mail to msg.ProfileMap.HelpDesk@msg.group).
Deactivating / deleting entities & relationships
The functionality ProfileMap provides for deactivating entities is described in the User Manual section “Deactivating terms” in the chapter “Data Curation”. Certain entities in the ontology play a special role in the ranking algorithm (see the section “Step 4: Searching” in the chapter “Search for candidates” in the User Manual). Deactivating these entities will not break the aspect similarity calculations used for the machine learning. Most of these entities are in the table of potential parent concepts or are parent entities of the ones in the table (see section “Step 4: Add parent concept” in chapter “Adding new entities and relationships via UI”). If one thinks of deactivating one of these entities and replacing it with a similar one that suits one’s use case slightly better, it is recommended to instead make this new entity a child node of the original one, so that the machine learning model is weighting the new entity and its children correctly.
Relationships of competencies can be deleted using the functionality described in the subsection “Editing Skills” (section “Editing existing Skills, Certificates, Clients”). Also, the relationships INSTANCE_OF, SUBCLASS_OF, USE, PART_OF and PROGRAMMING_LANGUAGE play a special role in the search filter and the ranking algorithm of ProfileMap’s search. Based on these relationships it is decided which related entities are considered when choosing the list of candidates returned for a search and in some cases which entities belong to which aspects that are used for ordering the search result list. Thus, one should only delete existing relationships of these types if one is certain that such a relationship is incorrect.